TL; DR
일단 솔직히 원인을 잘 모릅니다. 다른 블로그 찾아보세요 :( ....
요기가 좋아 보이네요: https://www.tabida.pe.kr/58
특히 검색 인덱싱 속도를 높이기 위해 "그룹 정책"에 들어가서 "PC를 사용 중이더라도 최고 속도 인덱싱" 옵션을 켜는 것이 인상적입니다. 저는 아직 못 써봤지만...
저의 경우는 PC 포맷 후 수많은 메일이 들어있는 메일 계정 로그인을 해 뒀을 때, 인덱싱이 매우 오래 걸릴 (이건 메일이 많으면 어쩔 수 없다네요.) 뿐더러 인덱싱 중인데 메일 검색을 시도했을 때 검색 결과로 최근 메일 일부만 뜨는 문제였습니다.
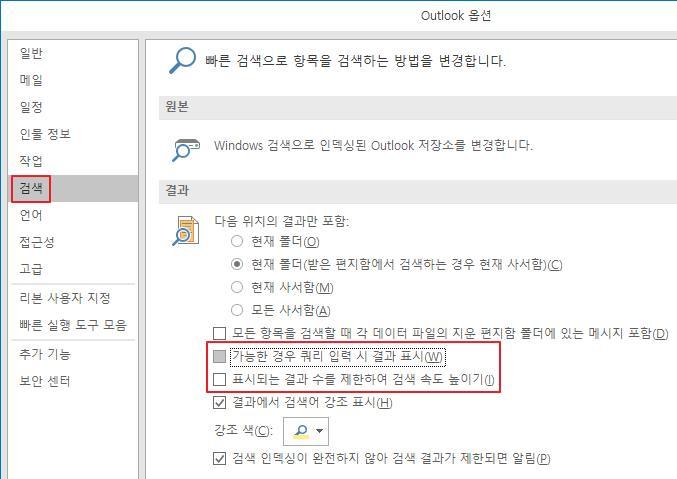
<Outlook 옵션 - 검색>에서 "가능한 경우 쿼리 입력시 결과 표시" 옵션을 꺼서, 인덱싱 결과를 쓰지 않고 검색하도록 하여(?) 문제를 우회했습니다.
아직 인덱싱 진행 중이라는 오류 메시지가 안 떴는데, 앞선 글처럼 비정상적인(?) 방법으로 계정 추가를 해서 그럴지 모르겠네요.
겪은 문제 증상
"인덱싱이 안 되었다"고 오류 메시지가 뜨지는 않으나, 결과 몇 개만 나오고 전체 결과는 안 나오는 상태였습니다. 인덱싱이 잘 안 되고 있는 상태였는데요.
- 인덱싱 상태를 보면 수만 건 메일 항목이 인덱싱을 기다리고 있다고 나타났습니다. 어림짐작이지만 10초당 100건씩 줄어드는 것 같았어요.
* 인덱싱 상태 보기
아웃룩 프로그램에서 검색란을 클릭하면, 위의 리본 메뉴에 [검색] 탭이 생깁니다.
클릭한 뒤 [검색 도구] > [인덱싱 상태]를 차례로 누르면 현재 인덱싱 프로그램이 뭘 하고 있는지 나옵니다.
알아서 새로고침되지 않으니, 인덱싱이 되어서 갯수가 줄긴 하는지 보려면 조금 있다가 직접 인덱싱 상태 창을 다시 열어주어어 합니다...
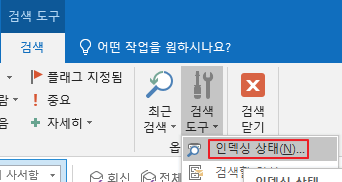
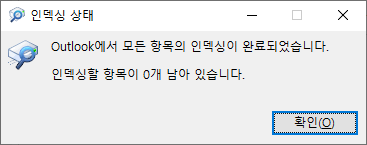
해결 아니고 우회 방법
파일 - 옵션 - 검색으로 들어가서 "가능한 경우 쿼리 입력시 결과 표시" 옵션을 껐습니다. 인덱싱 결과를 쓰지 않고 검색하도록 하는 것 같은데요, 요렇게 하니까 검색이 되기는 되더라구요.
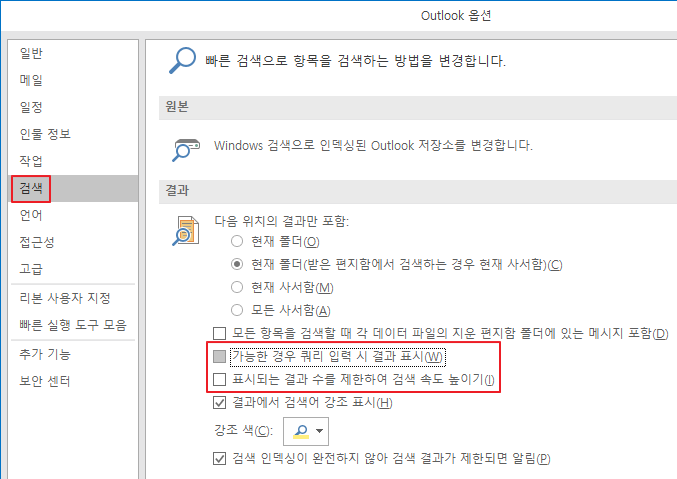
다만 인덱싱 결과를 안 쓰니 검색 속도가 느려진다고는 하는데... 일단 검색 되는게 우선이죠.
실패한 도전
- 메일함 파일 깨져서 색인이 안 되나 해서 MS오피스 프로그램 폴더에 있는 "ScanPST.exe" 프로그램을 돌려봤습니다. 항목 몇 개가 손상되었고 고쳤다고 했지만, 인덱싱 속도 개선에는 별 소용이 없더군요. 아니... 방금 로그인했는데 손상된 항목이 있다고요???
"ScanPST.exe"는 "C:\Program Files\Microsoft Office\root\Office16\"에 있었습니다.
64비트 OS, 32비트 오피스이면 "Program Files" 폴더 대신 "Program Files (x86)" 폴더에서 찾아주세요. - 아웃룩 검색 옵션에서 "표시되는 결과 수를 제한하여 검색 속도 높이기" 옵션을 먼저 꺼 봤지만 소용이 없었습니다.
가지 않은 길
- 정 인덱싱이 안 되면 "인덱스 재생성", 또는 아예 윈도 인덱싱 서비스를 포기하라고도 하더군요. 아무리 그래도 그건...
- 방금 찾아보니 PC 사용 중일 때 인덱싱 속도를 늦추지 않도록 하는 옵션이 있다고 하네요..
'팁' 카테고리의 다른 글
| LG폰 폰트 패키지 직접 만들기는 잘 안 됨 (2) | 2019.10.11 |
|---|---|
| Windows 10 꾸미기 효과 성능 무관하게 강제 적용 (0) | 2019.09.18 |
| 아웃룩 2019/365 IMAP 메일 주소와 로그인 계정이 다를 때 문제 해결 (0) | 2019.05.14 |
| Let's Encrypt: TLS-ALPN-01 (HTTPS 포트만 씀) 인증 방법을 Nginx 서버에 Dehydrated 이용해서 대충 도입하기 (0) | 2019.03.05 |
| Logrotate에서 띄우는 "File size changed while zipping" 메시지 피하기 (0) | 2019.02.19 |